本文来源于:2019第三届农村中小金融机构科技创新优秀案例评选,作者:江西农信
江西农信:异构双活的大数据基础平台
2019-10-23 关键词:大数据,农信/农商行,数据中心,基础设施,基础架构,灾难备份,业务系统建设 5037
5037
项目背景及目标
项目背景
全省农商银行经过十多年的信息化建设,逐步建立并不断完善了大数据平台V2.0、核心、信贷、卡系统、“两银”、POS、财管、公务卡等业务系统,积累了非常丰富的银行行为数据。并且,在2015年至今,不断优化和开展了多个平台的建设,包括流程银行项目三期、互联网金融一期、“两银”系统、FTP项目、CRM项目一期、财富管理系统建设等,为推进建设信息化银行,奠定了坚实的基础。
然而,随着国内外经济、金融环境的快速变化和互联网金融及其他业务的快速发展,现有的大数据基础工程建设还有待进一步夯实,大数据应用能力在服务内部管理、客户服务、风险管控等方面面临新的挑战。
此前我行数据平台基于一台Netezza一体机,且不间断运行已经近5年了,无论是从可靠性层面考虑,还是平台的可扩展性分析,都无法满足我行当前业务的快速发展,因此,亟需引入先进的架构纵深拓展现平台。
项目目标
平台应提供对海量数据进行采集、计算、存储、加工,同时统一标准和口径。数据统一之后,根据标准数据再进行存储,形成大数据资产层,进而为客户提供高效服务。
平台应具备分布式运行环境能力,全面的资源监控、管理、预警能力,全方位的数据处理和存储能力,行内不同业务层级的数据使用和服务能力,超强的大数据量、大数据容量的运算处理能力以及较高的系统运行稳定性、安全性和高容错能力,以满足大规模、超大规模数据量的处理和服务要求。
项目方案
建立一套以hadoop和GPU技术为基础的,集数据存储、加工、服务于一体的大数据基础平台,与原数据平台( Netezza 体系)组成行内异构双活大数据体系,两个平台同时向外提供大数据服务,即同时分担负载又互为备份,整体平台架构见下图:
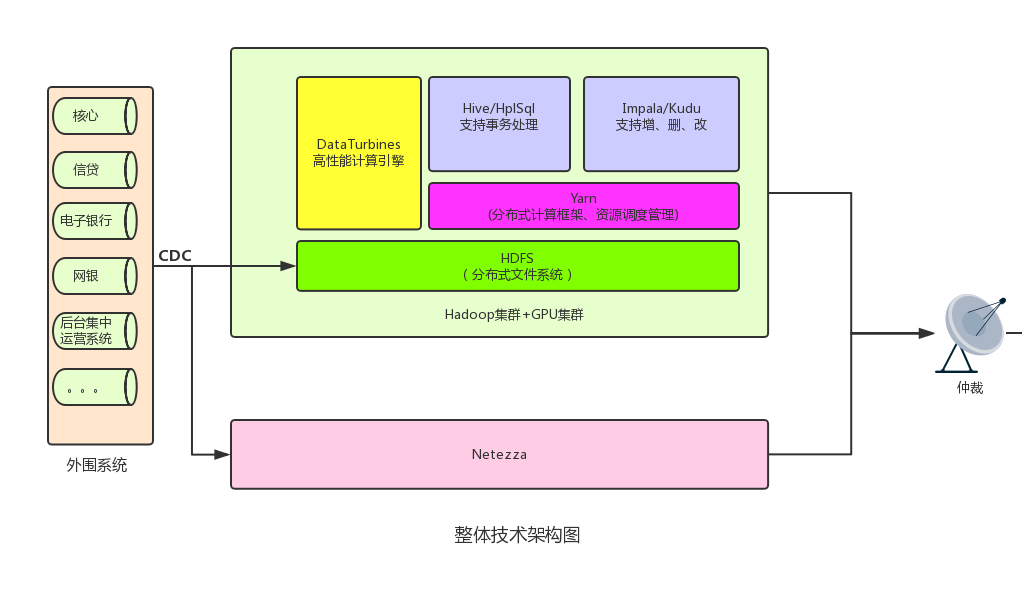
双活的大数据体系,既保留目前的Netezza体系,又扩展出新的技术架构,同时解决了单点的潜在风险,新的hadoop集群也得到充分利用。在数据安全方面,hadoop的一备多的方案大大提升数据安全性;hadoop基于分布式架构构建,大的特点就是易于搭建,便于通过扩展来提升性能,采用hadoop+GPU的混合式MPP架构,既符合大数据主流趋势,又通过GPU的高性能计算的特性,来提升整个平台的不同场景的适应能力(如高TPS的即席查询、计算密集型的数据加工及分析场景),整体平台综合性能指标得到大大提升。
异构双活的大数据基础平台整体共分为九个部分,包括了数据源、获取层、缓冲层、整合层、语义层、数据仓库、实时流处理、分析层以及应用层。
·数据源
大数据平台数据源主要来源于行内业务系统、第三方数据以及数字终端。
行内业务系统:包括信贷系统、网银系统、核心系统等所有系统中结构化数据以及非结构化数据等;
第三方数据:包括行内从外部系统获取的业务数据,例如与工商、人行交互数据等;
数字终端:包括手机APP、官网等终端业务数据以及点击流行为数据等。
·获取层
大数据平台数据获取方式主要通过批量数据获取(DataStage)、实时数据获取(CDC)以及流数据获取(例如日志、事件等数据资源)。
·缓冲层
数据缓冲区是用来存储近经常使用到的数据集,通常采用memcached、redis等技术。
·整合层
主要包括原始数据、基础数据、主题数据、事件数据、第三方数据以及汇总加工后的数据等。
·语义层
根据特定业务模型区分多种数据集市,多维的方式存储(包括定义维度、需要计算的指标、维度的层次等),提供决策分析等支持。
·分布式数据仓库
分布式数据仓库是决策支持系统(dss)和联机分析应用数据源的结构化数据环境。数据仓库研究和解决从数据库中获取信息,进行数据挖掘、自然语言学习,提供决策分析支持等。
·实时流处理(STREAMS)
实时流处理是将业务系统产生的数据进行实时收集,交由流处理框架进行数据清洗,统计,入库,并通过驾驶舱、可视化的方式对统计结果进行实时的展示。
·分析层
主要包括Cognos(多维报表、报表分析)、UNICA(实现一致和相关的跨渠道体验;通过高级分析和营销流程改进提升客户体验,包括事件营销、交互营销)、ECHART(驾驶舱、可视化管理)、自然语言处理NLP和STREAMS(行为分析、路径分析)。
·应用层
大数据应用可以在银行业务的各个方面提供支持,包括反欺诈、风险管理、客户营销、运营优化等,从而为企业带来更多的效益。
创新点
一、Hadoop+GPU体系的数据计算能力提升
Hadoop+GPU架构体系有效提升了平台的数据计算及处理能力,GPU在浮点运算、并行计算方面可以提供数十倍乃至于上百倍于CPU的性能,在其他指标,如能量消耗、带宽等方面也有很大的优势,为了提高平台的数据处理及计算效率和实时性,将GPU与hadoop进行强强联合,共同应用于数据处理及计算,充分利用系统服务器的资源。
二、多租户计算资源管理及数据模型的可视化开发
平台根据Kerberos认证和LDAP认证机制,通过多租户的方式管理所有的存储和计算资源(数量/状态/故障/调度),简化了租户计算资源的分配和收回,提升了平台计算资源的优化能力,包括CPU、GPU、内存、缓存、网络宽带等。
基于多租户计算资源管理能力,平台支持可视化的数据模型开发和统一的作业管理,建立不同数据分区,计算与访问分离,统一的数据模型开发标准,统一的SQL抽象,支持底层不同类型的存储组件,多种数据模型开发语言可视化管理(Spark、Hive、Python、Shell等类型),实现了较低成本的实施投入。
技术实现特点
系统采用Hadoop集群+GPU集群为一体的集群部署方式,GPU与Hadoop数据处理组件同时部署在相同的机器上,达到一台机器双倍查询性能。Hadoop+GPU架构体系与原数据平台( Netezza 体系)组成行内异构双活大数据体系。
Hadoop技术组件说明:
Hive分布式的数据仓库,提供MR的加工方式,Impala基于MPP架构的内存计算引擎,Impala与Hive的数据库可以共享,Cloudera提供了一个新的架构组件Kudu,Impala+Kudu的架构设计,解决impala对表的修改和删除操作,impala需要建立和kudu的映射表来共享数据。此次项目的大数据平台系统的应用组件包括了:HDFS、YARN、Centry、HIVE、IMPALA、ZOOKEEPER、KUDU、HPLSQL、Spark、Kafka等应用组件。
GPU技术应用说明:
DataTurbines (简称DT)采用GPU并行计算技术加快数据处理,开发出全新的高性能MPP(分布式计算)数据库,其特点在于在充分发挥GPU计算卡的计算单元多、带宽大、并发计算能力强,提高数据加工处理效率及数据即席查询统计并发能力及查询效率
DataTurbines的数据体系是基于内存的GPU加速式分布式数据库。数据层的顶端是GDDR,即GPU的高速DDR5显存,其拥有超过400GB/s的内部数据带宽,能大大加速数据的查询速度和能力。
DataTurbines的显存主要分为上图所示的几个区块(列数据集合区,动态结果区,HASH区,函数计算区,Join空间,Kernel运行区),各个区域大小不固定,每个区域是否存在以及其大小都由当前任务所决定,显存的分配由显存资源管理器统一管理。
项目过程管理
一、需求调研及讨论阶段
此阶段时间段为2018年8月至2018年9月,其间主要结合我行原有数据仓库(Netezza体系)情况进行调研及讨论,提交业务需求文档。
二、需求分析及设计阶段
此阶段起始时间为2018年9月至2018年10月,其间主要是根据业务需求文档,在分析需求的基础上进行系统方案设计。包括系统架构设计文档,概要设计文档,和详细设计文档等。
三、系统开发阶段
此阶段起始时间为2018年10月至2018年12月,其间完成了系统开发和功能实现。
四、系统测试、试运行准备阶段
此阶段从2018年12月至2019年3月,其间完成了测试计划、测试环境搭建、测试案例编写、功能测试、可靠性及压力测试等。
五、系统试运行阶段
此阶段起始时间为2019年3月至2019年7月,期间选定3个试点系统,进行大数据基础平台双活体系的生产部署对接。
六、系统上线阶段
项目实施严格按照项目管理相关制度,从计划、质量等多方面进行规范化管理,项目如期完成。至2019年7月中旬投产上线。
运营情况
系自系统上线后,Hadoop大数据基础平台与原数据平台( Netezza 体系)组成行内异构双活大数据基础平台,同时向外提供大数据服务。从系统性能方面,相比原单一的数据仓库(Netezza体系)在数据加工方面得到了显著的提高,目前平台整体数据加工作业执行情况如下:
·1分钟内任务完成情况平均占比89%;
·2分钟内任务完成情况平均占比97%;
·10分钟内任务完成情况平均占比98.7%;
·大于10分钟任务完成情况平均占比0.7%
平台采用多租户管理方式,大数据应用服务能力得到加强,行内业务需求得到快速支撑,提高了项目交付的时间及效率;从业务支撑方面,能够更快、更准确的支持数据模型展现,提供更精准的数据服务。
项目成效
平台具有连接、管理、治理来自异构存储模式的数据,并支持不同的计算框架和作业类型,服务于前台不断变化的数据应用。
一、数据加工
高速的数据查询,DataTurbines采用MPP架构,与hadoop组件impala同时部署在相同的机器上。DataTurbines是一个纯GPU架构的服务器,主要工作负载都由GPU承担,对CPU性能要求不高。因此与hadoop数据节点共享部署,能同时对外提供数据服务,达到一台机器双倍查询性能。
统一的SQL抽象,支持底层不同类型的存储组件。
二、数据集成
数据集成是指从外部不同类型的数据源将数据采集接入到统一的某个目的地。数据可能来自关系型数据库的数据,来自文件,来自IOT设备的实时数据;目的地可能是Hadoop大数据平台或原数据仓库(Netezza体系),也可能是普通关系型数据库或者NoSQL数据库。
·Connector连接器: 支持多样性的数据源和管理。
·Source 源:支持批量抽取和CDC模式实时抽取远程数据成标准化的数据格式到消息中间件。
·Sink目的地: 支持多目标数据流入。
三、数据报表
数据可视化:面向业务人员/数据工程师/数据分析师/数据科学家,致力于提供一站式数据可视化解决方案。
多数据源支持:支持多种异构存储系统,用户只需要配置连接信息,即可以各种方式展示数据。
四、多租户和计算资源
多租户管理:平台支持多租户的方式管理所有的存储和计算资源。按照租户需要对平台进行资源分配和调度,查看历史的资源消耗情况。
权限管理:将平台上的所有的资源按照不同的角色设置为平台管理员、租户管理员和普通用户,在线配置访问权限,保证数据安全。
经验总结
在此项目进展中,我行在大数据基础建设方面获得了宝贵的经验,随着技术的进步和大数据平台的发展,我行数据架构的发展还需进一步加强。
一、由数据被动支撑业务,提升到数据主动服务业务
异构双活的大数据基础平台不光是一次成功的技术和业务创新性的实践,更给本行及同业在大数据应用领域树立了一个可供借鉴的成功模版。后续可进一步拓展大数据技术在行内的应用,全面提升银行业务水平,拓展新的银行产品和服务。
建设双活的大数据基础平台,由现在的数据被动支撑业务,提升到数据主动服务业务,部分业务领域达到数据引领创新。整合银行业内外信息,充分发挥大数据新技术优势,构建具有特色、业界领先的智能“数据”分析能力。
二、探索流式计算,进行业务实时监控,降低业务风险
传统的IT系统基本只能提供T+1的、由简单归纳总结的数据构成的统计分析报表。流式计算平台提供高可靠、高容错、高性能的实时海量事件捕获处理与计算能力,并做为一种公共能力提供给各个系统内实时计算业务场景的需要,为各应用系统的实时计算提供集中统一的公共支持能力。
本网站案例,除特殊标明来源的,版权归金科创新社所有,未经许可不得转载,否则将视为侵权,对于不遵守此声明或者其他违法使用本文内容者,本网站依法保留追究权。另,本网站部分案例、观点文章来源于网络素材,如有侵权,请邮件联系 fenglei@fintechinchina.com 处理!
特别提示: 本网站免费为广大金融企业提供IT选型咨询服务,详情点击 【 需求提交 】。
推荐阅读
更多
河南农信:基于大数据平台的智能审计管理信息系统
随着河南省农村信用社各项业务的飞速发展及信息化建设的不断深入,创新性金融产品和金融服务不断涌现,业务数据和业务流程复杂程度不断提高,交易信息和管理信息不断膨胀。
 2018第二届农村中小金融机构科技创新优秀案例评选
2018第二届农村中小金融机构科技创新优秀案例评选
 河南农信
河南农信
 2019-10-23
2019-10-23
安徽农信:基于人工智能的滨湖数据中心基础设施能效优化
数据中心基础设施能耗巨大,数据中心节能能够带来显著的经济和社会效益。而在数据中心基础设施中,空调能耗又占到全部能耗的70%,本项目通过将人工智能应用到数据中心基础设施空调系统运行控制中,为安徽省联社乃至金融行业数据中心基础设施节能降耗探索一条智能化创新的道路。
2018第二届农村中小金融机构科技创新优秀案例评选
安徽农信
2019-10-23
湖北农信:智慧学习平台
智慧学习平台的建设广泛运用互联网新媒体技术,集教、学、练、考评等要素,通过数字化学习运营将其打造为兼容、开放、共享、规范的多元一体化学习载体,成为全省农商行系统的学习中心,考试中心、直播中心、制度图书中心、员工交流中心,有效地提高了员工学习的时效性、便捷性和覆盖面,成为全省农商行“智慧银行”的建设重要载体。
第五届农村中小金融机构科技创新优秀案例评选
湖北农信
2019-10-23
江西农信:“百福快贷”项目
网络信贷项目依托互联网技术,采用全流程“不落地”线上操作模式,以大数据应用为基础,实现贷款申请受理、审批、放款、回收和贷后管理全部在线完成,整个贷款审批流程无需人工参与,实现了系统几分钟内自动产生审批结果,真正意义上达到了可足不出户就可完成贷款申请和收到贷款的目标。
2018第二届农村中小金融机构科技创新优秀案例评选
江西农信
2019-10-23
江苏省联社:风险偏好与限额管理系统
本项目旨在建设统一风险数据集市,打通风险管理相关数据,建立风险偏好与限额管理系统,提高各类风险识别、计量、监测和数据分析的能力,并提供给农商行风险管理相关的数据支撑,以帮助农商行进行合理的业务拓展与风险管理决策。
第五届农村中小金融机构科技创新优秀案例评选
江苏省联社
2019-10-23
重庆农商行:基于数据决策的全线上零售信贷产品“渝快贷”
“渝快贷”是重庆农商行推出的基于数据决策的个人全线上信用消费贷款产品。
2018第二届农村中小金融机构科技创新优秀案例评选
重庆农商行
2019-10-23
 选型库
选型库
金融行业全面的数智化创新解决方案,涵盖历届“鑫智奖”参评方案及选型库会员机构提交的金融行业解决方案




微信
咨询

 微信咨询
微信咨询

扫码添加金科小助手微信号
咨询案例和解决方案相关信息
或联系对应机构


